%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import math, warnings
import seaborn as sns
from mpl_toolkits.mplot3d import Axes3D
from random import random
#from mpl_toolkits.mplot3d import axes3d
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import KFold
sns.set()
warnings.filterwarnings('ignore')
Polynomial Regression is a type of regression supervised algorithm in which the relationship between feature vector $X$ and target one $Y$ is an $n^{th}$ degree polynomial function.
We gonna use the data set which is prepared in advance using $3^{th}$ degree polynomial
$$y_i = f(x_i) = \theta_3x_{i}^3 + \theta_2x_i^2 +\theta_1x_i + \theta_0 + \varepsilon_i $$
$$ \; \; \; = x - 2x^2 + 0.2x^3 + \varepsilon_i $$
The $\varepsilon$ is Gaussian distributed with mean zero and some variance $\sigma$
$$𝜀 \sim N(0,\sigma^2) $$
np.random.seed(0)
x = np.linspace(-5,10,num=30) #generate the X data
y = x - 2 * (x ** 2) + 0.2 * (x ** 3) + np.random.normal(-5, 5, size=x.size) +2 #generate target points y
x = x[:, np.newaxis]
y = y[:, np.newaxis]
plt.scatter(x,y, s=10)
plt.show()

Now we gonna use already prepared data and we will try to find the best fitting polynomial using some regression model.
def regression(model, x_train, y_train, x_test, y_test) :
std = StandardScaler().fit(x_train)
regr_type = model.fit(std.transform(x_train),y_train)
y_predicited = regr_type.predict(std.transform(x_test))
return y_predicited, regr_type.score(std.transform(x_train), y_train),regr_type.score(std.transform(x_test),y_test), regr_type.coef_
y_pred, score_train, score_test, coef = regression(LinearRegression(), x, y, x, y)
y_pred, score_train, score_test , coef = regression(LinearRegression(), x, y, x, y)
plt.plot(x, y_pred) #L = 0.0028
plt.scatter(x, y, s=10, color='r')
plt.title('accuracy = {}'.format(score_train))
Text(0.5, 1.0, 'accuracy = 0.16333333102399328')

As we can see above, using a straight line we've achieved approx 16% accuracy which is too bad. In that case, when the model is too simple to fit the data we say the model is an underfitting . The simple linear regression is not able to capture the points well, this called high bias . Model with high bias pays very little attention to the training data and oversimplifies the model. It always leads to high error on training and test data. We can boost the model by increasing the degree of the polynomial. We can add new features that are powers of the original one.
Thus we can improve the model from $Y = \omega_0 + \omega_1x$ to $Y = \omega_0 + \omega_1 x^1 + ... + \omega_p x^p$ but the problem still remains linear because $Y$ is multi linear dependented to $x_i^j$.That means we can use again the LinearRegression(). We will tranform the data into $39^{th}$ degree polynomial.
def polynomial_convert(X,degree):
'''
X : like array
dataset
degree : int
number of powers
'''
return PolynomialFeatures(degree=degree).fit_transform(X)
x_poly = polynomial_convert(x, degree = 39)
y_pred, score_train, score_test, coef = regression(LinearRegression(), x_poly, y, x_poly, y)
plt.plot(x, y_pred) #L = 0.0028
plt.scatter(x,y, s=10,color='r')
plt.title('accuracy = {}'.format(score_train))
Text(0.5, 1.0, 'accuracy = 0.9999507021155106')

We can see that the accuracy of $39^{th}$ polynomial is 99.9%. This model cannot be right because the data set has uncertainty. When the model fits the uncertainty(error or bias) that is called overfitting or the model has high variance . On new unseen data the model will perform bad result.
There are quite a number of techniques that help us to prevent overfitting. Regularization is one such technique. Regularization basically aims at proper feature selection to avoid over-fitting.
This is a regularization technique used in feature selection using a Shrinkage method also referred to as the penalized regression method. Lasso is short for Least Absolute Shrinkage and Selection Operator, which is used both for regularization and model selection. If a model uses the L1 regularization technique, then it is called lasso regression.Lasso regression achieves regularization by completely diminishing the importance given to some features (making the weight zero).
The lost function of the Lasso is the ordinary least square with constraint optimization.
$$J(\varTheta) = \frac{1}{2m}\sum_{i}^n( y_i - \sum_j^mx_{ij}\theta_j)^2 $$
$$subject \; to \hspace{1cm} \sum_j^m|\theta_j| < \lambda $$
Using langrange multiplyer the solutions of above equtions is :
$\lambda \sum_j^m|\theta_j|$ represens the penalty
A tuning parameter, $λ$ controls the strength of the L1 penalty. $λ$ is basically the amount of shrinkage:
Lets investigate what the lasso will perform,we gonna use </mark> Lasso </mark> from sklearn
x_poly = polynomial_convert(x, degree = 12)
y_pred, score,score_test, coef = regression( Lasso(alpha=0), x_poly, y, x_poly, y)
plt.plot(x, y_pred) #L = 0.0028
plt.scatter(x,y, s=10,color='r')
plt.title('accuracy = {}'.format(score))
Text(0.5, 1.0, 'accuracy = 0.9338410468831142')

In above we've used the $12^{th}$ degree polynimial and Lasso with alpha=0. We will train lasso with different tuning parameters $\lambda= [10^{-4},10^{-3},10^{-2},10^{-1},1]$ in order to to get the their impact on the model.
def calc_weights(model, alphas):
weights = np.array([])
for alpha in alphas:
y_pred, score, score_test,coef = regression( model(alpha=alpha), x_poly, y, x_poly, y)
if weights.shape[0]>0 :
weights = np.vstack([weights,coef])
else :
weights = coef
return weights.T
def plot_weights(weights):
for i in range(weights.shape[0]):
plt.plot(np.array(alphas),(weights[i,:]),label=r'$w_{}$'.format(i))
plt.ylabel('weight size')
plt.xlabel(r'$\lambda$')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0)
alphas = [10e-4, 10e-3, 10e-2,10e-1,1]
weights = calc_weights(Lasso, alphas)
plot_weights(weights)

From the above graphic, we can notice that when $ \lambda $ is increased then the weights (predictors) $ w_i $ goes to zero, also the important thing that we have to point out is the rate of decreasing of $ w_i $ is related to its size $\frac {\partial w_i} {\partial \lambda} = C.w$.
Let's see with bigger $\lambda= [1,10,20,30,100]$
weights = np.array([])
alphas = [10e-1,1,5,7,10,20]
weights = calc_weights(Lasso, alphas)
plot_weights(weights)

From above graph we see that with enough big $\lambda$ the weights get a zero. Because of that fact we can use Lasso for feature selection.
The lasso performs shrinkage so that there are "corners'' in the constraint, which in two dimensions corresponds to a diamond. If the sum of squares "hits'' one of these corners, then the coefficient corresponding to the axis is shrunk to zero.

We've seen that the regularisation process is controlled by the alpha parameter in the Lasso model. With higher alpha, some features get zero. As we've found that alpha with which the model works well and if some of the weights are zero we could drop the features related to these weights. Thus we make a feature selection.
Let's try to find the best alpha
X_train, X_test, y_train, y_test = train_test_split(x_poly, y, test_size=0.33, random_state=42)
weights = np.array([])
alphas = [10e-4,10e-3,10e-2,10e-1,10,100,1000]
scores =[]
scores_test = []
print(weights.shape)
for alpha in alphas:
y_pred, score, score_test, coef = regression( Lasso(alpha=alpha), X_train, y_train, X_test, y_test)
scores.append(score)
scores_test.append(score_test)
if weights.shape[0]>0 :
weights = np.vstack([weights,coef])
else :
weights = coef
weights = weights.T
(0,)
x_label=np.linspace(0,1,len(scores))
plt.plot(x_label,scores,label='train')
plt.plot(x_label,scores_test,label='test')
plt.xlabel('alpha')
plt.ylabel('scores')
plt.xticks(x_label, np.array(alphas).astype(str))
plt.legend()
<matplotlib.legend.Legend at 0x279c951940>

scores_test
[0.9424123436147908, 0.9441978248338849, 0.9452458362554361, 0.7075732312580467, -0.015979696071850125, -0.015979696071850125, -0.015979696071850125]
For $\alpha$ higher than $0.1$ both train and test accuracy are getting to decrease. Therefore from the graph, we can point $0.1$ as the best $\alpha$ for which the model achieved $0.94%$ on test data.
y_pred, score,score_test, coef = regression( Lasso(alpha=0.1), x_poly, y, x_poly, y)
plt.plot(x, y_pred) #L = 0.0028
plt.scatter(x,y, s=10,color='r')
plt.title('accuracy = {}'.format(score_test))
Text(0.5, 1.0, 'accuracy = 0.9319986935578851')

For the predictors of model (weights) we have :
coef
array([ 0. , 4.32734531, -52.88751358, 44.6197943 ,
0. , 9.05931541, 0. , 0. ,
0. , 0. , 0. , 0. ,
0. ])
We can make feature selection by selecting only the columns (features) with non-zero weights and creating new data set.
print('important features : ',np.nonzero(coef))
important features : (array([1, 2, 3, 5], dtype=int64),)
x_data_new = x_poly[:,(1, 2, 3, 5)]
Let's try to train a new model using only the selected features by Lasso into Linear Regression.
y_pred, score_train, score_test, coef = regression(LinearRegression(), x_selected_feature, y, x_selected_feature, y)
plt.plot(x, y_pred) #L = 0.0028
plt.scatter(x, y, s=10, color='r')
plt.title('accuracy = {}'.format(score_train))
Text(0.5, 1.0, 'accuracy = 0.9334067494986096')

print('old data set shape', x_poly.shape)
print('new data set shape', x_selected_feature.shape)
old data set shape (30, 13) new data set shape (30, 4)
We've achieved the same result although dimensionally of the data is reduced from (30,13) to (30,13).
Ridge regression as the Lasso is form of regularized regression.The both methods seek to alleviate the consequences of multi-collinearity, poorly conditioned equations, and overfitting.
Ridge regression as Lasso is motivated by a constrained minimization problem, which can be formulated as follows:
The lost function of the Lasso is the ordinary least square with constraint optimization.
$$J(\varTheta) = \frac{1}{2m}\sum_{i}^n( y_i - \sum_j^mx_{ij}\theta_j)^2 $$
$$subject \; to \hspace{1cm} \sum_j^m\theta_j^2 < \lambda $$
Using a Lagrange multiplier we can rewrite the problem as: $$RidgeLost = J(\varTheta) = \frac{1}{2m}\sum_{i}^n( y_i - \sum_j^m x_{ij}\theta_j )^2 + \lambda \sum_j^m\theta_j^2$$
alphas = [10e-4, 10e-3, 10e-2,10e-1,1]
weights = calc_weights(Ridge, alphas)
plot_weights(weights)

weights = np.array([])
alphas = [10e-1,1,5,7,10,20]
weights = calc_weights(Ridge, alphas)
plot_weights(weights)

Ridge regression decreases the complexity of a model but does not reduce the number of variables since it never leads to a coefficient been zero rather only minimizes it. Hence, this model is not good for feature reduction.
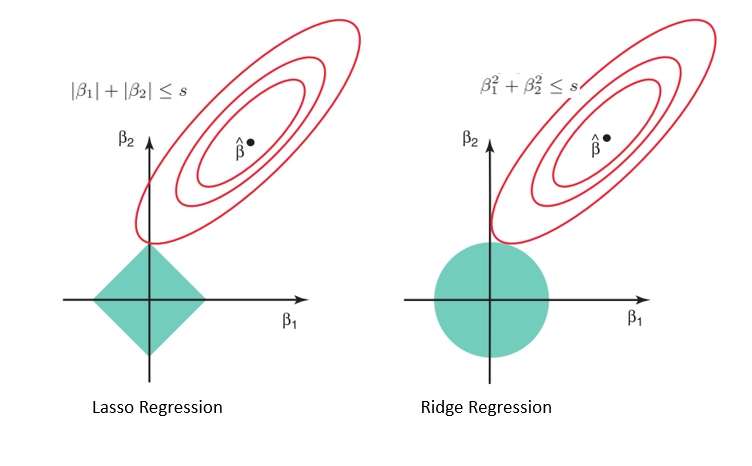
Considering the geometry of both the lasso (left) and ridge (right) models, the elliptical contours (red circles) are the cost functions for each. Relaxing the constraints introduced by the penalty factor leads to an increase in the constrained region (diamond, circle). Doing this continually, we will hit the center of the ellipse, where the results of both lasso and ridge models are similar to a linear regression model.
However, both methods determine coefficients by finding the first point where the elliptical contours hit the region of constraints. Since lasso regression takes a diamond shape in the plot for the constrained region, each time the elliptical regions intersect with these corners, at least one of the coefficients becomes zero. This is impossible in the ridge regression model as it forms a circular shape and therefore values can be shrunk close to zero, but never equal to zero.
Cross-validation is a resampling method that uses diferent portions of the data to test and train amodel on diferent iterations.The goal of cross-validation is to test the model's ability to predict new data that was not used in estimating it, in order to flag problems like overfitting.
In k-fold cross-validation, the original sample is randomly partitioned into k equal sized subsamples. Of the k subsamples, a single subsample is retained as the validation data for testing the model, and the remaining k − 1 subsamples are used as training data. The cross-validation process is then repeated k times, with each of the k subsamples used exactly once as the validation data. The k results can then be averaged to produce a single estimation. The advantage of this method over repeated random sub-sampling (see below) is that all observations are used for both training and validation, and each observation is used for validation exactly once. 10-fold cross-validation is commonly used,[16] but in general k remains an unfixed parameter.
Let's implement the k-fold cross-validation
kfold = KFold(3, True, 1)
# enumerate splits
for train, test in kfold.split(x_poly):
print('train: %s, test: %s' % (train, test))
train: [ 0 1 2 4 5 6 7 8 9 11 12 13 15 16 18 23 25 27 28 29], test: [ 3 10 14 17 19 20 21 22 24 26] train: [ 0 3 5 8 9 10 11 12 14 15 16 17 19 20 21 22 24 26 28 29], test: [ 1 2 4 6 7 13 18 23 25 27] train: [ 1 2 3 4 6 7 10 13 14 17 18 19 20 21 22 23 24 25 26 27], test: [ 0 5 8 9 11 12 15 16 28 29]
Example of spliting the data into 3 folds.
def cross_vall(model, x, y, folds=3):
'''
model : class
ML model
x,y : like array
data set
number_of_splits : int
number of folds
Return : float
Acuracy score
'''
kfold = KFold(folds, True, 1)
scores= []
for train, test in kfold.split(x_poly):
y_pred, score_train, score_test, coef = regression(model,x[train],y[train],x[test],y[test])
scores.append(score_test)
return scores
x_poly.shape
y.shape
(30, 1)
alphas = [3*10e-3,10e-3,10e-2,10e-1,0.03,0.07,0.06,1,5,7]
scores = []
for alpha in alphas:
scores.append(np.array(cross_vall(Ridge(alpha=alpha),x_poly,y,folds=3)).mean())
scores
[0.6749867782522502, 0.6992735672162587, 0.6126383374897085, 0.5080270426575648, 0.6749867782522502, 0.6292747814704289, 0.6378164724640704, 0.5080270426575648, 0.2652262616536486, 0.21533345216005315]
x_label=np.linspace(0,1,len(scores))
plt.plot(x_label,scores,label='test')
plt.xlabel('alpha')
plt.ylabel('scores')
plt.xticks(x_label, np.array(alphas).astype(str))
plt.legend()
<matplotlib.legend.Legend at 0x279d239310>

from graphic we can see that the in $\alpha=0.1$ the model achieved the best accuracy
y_pred, score_train, score_test, coef = regression(Ridge(alpha=0.01),x_poly,y,x_poly,y)
plt.plot(x, y_pred) #L = 0.0028
plt.scatter(x, y, s=10, color='r')
<matplotlib.collections.PathCollection at 0x279d1dbf40>

print(coef)
[[ 0. 5.31024478 -55.9286906 37.39814768 3.69289909 29.54764287 -3.1647536 -1.63375861 -10.73401512 -6.97375026 -3.63912415 2.79407099 8.46307391]]
